




引子
最近,方方日记这事儿挺火的。
什么?已经不火了?
哦,那也没有关系,反正追热点也不是我的强项。实际上,这事儿它火过或者还在火着,本身就不正常。在一个人们可以畅所欲言、出版自由、每天有成千上万各种观点的书籍出版的社会,大家早就见怪不惊了,一人一时的观点,很难火起来。
不管怎么说,它火过(或者还火着)最明显的标准就是人们对它两极化的评价。喜欢《方方日记》的认为它终归是一段有价值的材料,因为它来自于一位身处疫情中心之人的切身感受。讨厌《方方日记》的人则认为它暴露了过多的阴暗面,正能量不够,尤其是还在国外出版,有给“境外反华势力”递刀子的嫌疑。
不过,有意思的是,无论是支持的还是讨厌的,真正读过《方方日记》的人似乎不多,因为我观察网络上的论战大多都是情绪发泄,而没有证据支持。
我也没有读过《方方日记》,也没有打算读——我只喜欢读经过时间验证的经典,不太喜欢追热点。不过,我打算让电脑程序帮我读一下,告诉我《方方日记》到底是在赞扬抗疫精神、中立记录抗疫过程、还是在刻意抹黑抗疫成果。
怎么做呢?
情感倾向分析
自然语言处理技术有一种应用叫“情感倾向分析”,英文是sentiment analysis。也就是分析一段文本,判断这个文本在感情上是消极的还是积极的。这个技术对政府部门和对商家都很有用。政府部门可以用来分析舆情,了解人们对某项政策的反应。商家可以用来分析消费者的反馈,掌握人们对商品或者服务的态度。
做这种情感分析,最“简单粗暴”的方法,就是先人工把一种语言里的词汇都按照情感倾向标注了,积极的标注0到1的值(值越大越积极),消极的标志-1到0的值(值越小越消极),中性的就标为0。至于标注的颗粒度,就是标注者自己掌握了。分析也是简单粗暴,把文本里面的词汇的值,加起来,取个平均数就搞定了。
你可能觉得这样做很不“智能”,但实际上,现在一些流行的情感分析工具,就是这样做的,比如用于python的英文情感倾向分析库TextBlob。其实,在人工智能领域,人工的部分还是很多的。
很多有监督的机器学习模型,都依赖于高质量的人工标注。像自然语言处理经常用到的wordnet,就是人工一个词一个词建的。做这种事儿需要极大的耐心,对做这种基础工作的人,我是佩服得五体投地。
不过,我不打算用这种“简单粗暴”的方式,而是用智能一点的机器学习模型。当然,我也不打算自己去训练模型,虽然对我来说这事儿做起来不难,但没有必要重复造轮子。所以,我打算直接调用百度AI开放平台里面的情感倾向分析模块,让它来帮我“读一读”《方方日记》,看一下它的情感倾向。
做这事儿可以分五步:
获得文本。
清理文本。
分析情感倾向。
生成图表。
其它后续分析。
下面我就简单的描述一下分析的过程和结果。放心,即使你不懂计算机编程和自然语言处理,也完全可以看懂下面的分析。我也会提到一些技术细节,以供有知识背景的读者参考。
先申明一下,我不是计算机专业的,也不是专业程序员。虽然python编程、数据库处理、机器学习和深度学习我都略懂一点,但仅仅用于辅助我的语言学研究,谈不上深入。所以,我写程序的标准就是“能跑出结果就行”,至于是不是效率最高、模型最优化,不在我考虑范围之内,还望计算机高手们勿喷。
所有用于分析的文本和python代码我都打包好了,后台回复“方方日记”即可获取下载链接。
获得文本
分析的第一步当然是准备好材料,所以我需要《方方日记》的文本。哪里找呢?当然是网上下载。搜索了一下,发现财新网保存有《方方日记》60篇。好了,就从财新网下载。
方方日记2.png” alt=”” width=”450″ height=”750″ />
下载这种“笨活”,最好还是交给代码来做,所以我就写了一个简单的爬虫,来自动下载所有日记。
代码示例:
from bs4 import BeautifulSoup
from collections import defaultdict# 财新网保存有《方方日记》60篇,网址如下
base_url = r”http://m.app.caixin.com/m_topic_detail/1489.html”#获取每篇日记的网址,并保存在一个字典里(方便后面生成dataframe)
headers = {‘User-Agent’: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36’}
base_page_content = requests.get(base_url, headers=headers).text
soup = BeautifulSoup(base_page_content, “lxml”)
diary_data = defaultdict(list)# 观察base_page可知,日记相关信息都在<li></li>标签内。解析所有<li></li>标签。
for index, li in enumerate(soup.find_all(‘li’)):
try:
# 保存日记发表日期,标题和网址为一个元组
diary_data[index] = [li.em.text, li.a[‘title’], li.a[‘href’]] except Exception as e:
print(e)
import time
这段爬虫代码很简单,只有两个地方需要注意:一、下载间隔时间最好设长点,随机数字更好,财新网对机器人不是很友好。二、保存文本时,最好用gbk编码,因为百度AI处理中文,默认用gbk。用unicode也不是不可以,但是设置上会麻烦一些。
清理文本
搞数据科学的常说这么一句话:Garbage in, garbage out。喂的是垃圾,出来的也是垃圾。这说明清理数据的重要性。据说数据科学家75%的时间都是花在清理数据这样的“烂事儿”上。
我不是数据科学家,但我信这句话,因为每次我做语料库分析,大半儿时间都是花在清理文本上。
好在这次的文本不需要怎么清理,只是需要改一下文件名。下载的时候,我是按照日记标题生成的文件名。我只能这么做,因为财新网上方方日记的发表日期和日记日期不是一一对应的,再加上方方在日记里,一会儿用公历,一会儿用农历,没法生成统一格式的文件名。
这个部分我就手动处理了,好在一共也只有60个文本。处理过后,文件名格式统一为:nn-yyyymmdd.txt。比如2020年1月25日的日记是第一篇,那么文件名就是01-20200125.txt。
分析情感倾向
好了,文本准备好了,开始分析。这一步反而是最简单,写好代码,让它自己跑就是了。
代码示例:
# 连接百度情感倾向分析API
from aip import AipNlpAPP_ID = ‘yourid’
API_KEY = ‘your api key’
SECRET_KEY = ‘your secret key’client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
注意,代码不是完整版本,完整版本请后台回复“方方日记”下载。
百度的情感倾向分析引擎分析一段文本后,会给出四个数值,分别是:
积极概率:一个0到1的数,超过0.5,则说明文本积极概率高过消极。
消极概率:一个0到1的数,超过0.5,这说明文本消极概率高于积极。
情感倾向:0、1、2这三个数值。0表示消极,1表示中性,2表示积极。
置信度:一个0到1的数,表示前面三个数值的可信度有多高,比如,0.99表示上面三个数字99%的概率是可靠的。
显然,积极概率和消极概率相加总是等于1,因为它们是对应的嘛。我做了两个分析。一个是把方方日记60篇放在一起,当做一个整体,分析其情感倾向,结果如下:
积极概率:0.384
消极概率:0.616
情感倾向:0
置信度:0.740
也就是说,从整体来看,《方方日记》负向情绪概率高于正向情绪,情感倾向判断为负向(0)。
第二个分析是每一篇日记单独生成情感倾向值,观察方方写日记的60天里,情感倾向的变化。这个结果我就用折线图来表示了。
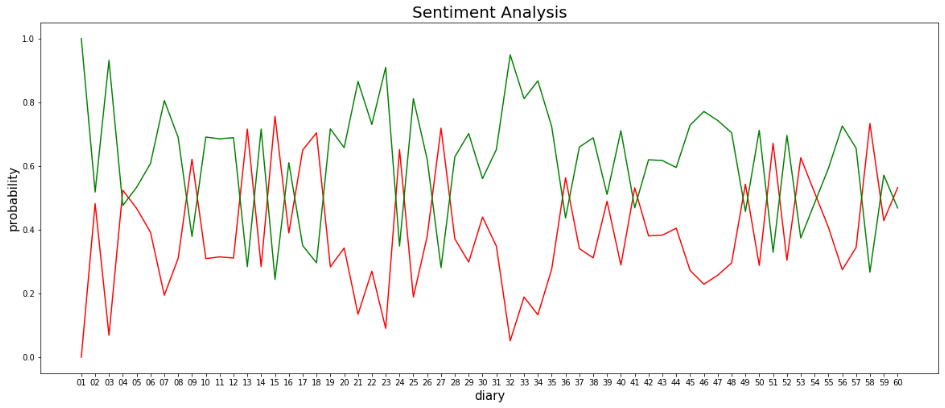
上图中,红色是正向倾向概率,绿色是负向倾向概率,因为二者相加总是等于1,所以两天曲线是对称的。观察折线图,可以粗略得出四个结论:
1.负向概率的高点比正向概率的高点高得多,也就是说,当某天的日记是负向情绪时,负向很明显,当某天日记是正向情绪时,正向不那么明显。
2.日记为负向情绪的天数多于日记为正向情绪的天数。数据显示,60篇日记里,18篇是正向情绪,1篇是中性,剩下41篇为负向情绪。
大部分日记的情绪概率都在0.35-0.65之间,概率高于0.8或低于0.2的比例很小。
实际上,只有9篇日记的负向概率高于0.8,占比小于20%。
负向情绪有三个小高峰,分别对应1月25日,2月16日和2月25日。
正向情绪也有三个小高峰,分别对应2月8日,2月20日和3月22日。
词云分析
一般来说,数值比较特殊的地方,都值得进一步分析。下面我们来看一下,几个小高峰分日记里分别写了些什么,让方方如此沮丧或愉快。当然,我还是不打算读日记,所以就分别给这几篇日记生成一个词云,来看一下关键词吧。
做中文词云,首先需要分词,也就是要像英文那样,在词与词之间有空格,比如这样:
做 中文 词云 , 首先 需要 分 词 。
分词我们用jieba这个python库。做词云就用常用的wordcloud库。我没有去搞那些fancy的图片背景,就使用了默认样式,用jupyter notebook直接显示了。
代码示例:
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as pltfilenames = [’01-20200125.txt’, ’23-20200216.txt’, ’32-20200225.txt’,
’15-20200208.txt’, ’27-20200220.txt’, ’58-20200322.txt’] fontpath = r’msyh.ttc’def make_cloud(file):
with open(file, ‘r’) as f:
text = f.read()
text = ” “.join(jieba.cut(text))
wordcloud = WordCloud(font_path=fontpath).generate(text)
return wordcloudfor file in filenames:
wordcloud = make_cloud(file)
%pylab inline
plt.imshow(wordcloud, interpolation=’bilinear’)
plt.axis(“off”)
plt.show()
结果如下。先来看让方方日记负面概率最高的那些日子发生了什么。
1月25日词云

这是方方日记的第一篇,也是负向概率最高的一篇。从关键词来看,方方感到不高兴的事儿和“微博”有关。至于什么“发出”了什么,“导致”了什么,仅从词云上看不出来,不过“爆粗”这个显示方方可能确实比较不爽。
2月16日词云

关键词里有“医院”“灾难”“恐慌”“病人”“疫情”等,的确是封城进入20天的真实写照。里面出现了一个人名“项立刚”,我不认识,也不想深究。
2月25日词云

关键词里有“隔离”“蔬菜”“疫情”等,看来,这篇日记里,方方表达了“蔬菜”捐赠出现问题的不满。
下面我们再来看方方日记里正向情绪概率最高的日子发生了什么。
2月8日词云

有点儿意思。关键词里出现了“政府”“湖北”这样的字眼儿。要知道,在负向情绪概率最高的日记里,“政府”不是高频词,“湖北”也不是高频词。而在正向情绪概率最高的日记里,“政府”和“湖北”都出现了。
这里,其实我们已经可以得出一个初步结论,方方日记的负面情绪主要针对事情,而涉及到抗疫的人和机构时,方方表达的是正向情绪。
2月20日词云

3月22日词云

这两个词云也有点意思,里面分别出现了“同学”和“朋友”这两个关键词。经常有人批评方方道听途说,总是从同学、朋友那里得到坏消息。但数据表明,在负向情绪概率最高的日记里,“同学”和“朋友”都不算高频词,而在这两篇篇正向情绪概率最高的日记里,“同学”和“朋友”分别是高频词。可见,方方从同学、朋友那里得到的不一定总是坏消息。
结语
从上面的分析我们可以大致得出以下结论:
1.方方日记负向情绪概率高于正向情绪。
2.日记的负向情绪主要针对事情,而针对政府时,可能更多是正向情绪。
3.方方从同学、朋友那里获得的消息不一定总是坏消息,可能好消息概率更高。
以下是基于上面观察的个人观点:
1.身在疫情中心,写出日记,负向情绪更多,是正常的,可以理解。
2.方方日记对事不对人,虽然负向,却称不上是“抹黑”。
3.如果描述事实是抹黑的话,科学家的主要工作就是抹黑了。
方方日记里很多事情的来源可能不可靠,但这些事情不都是负面的,所以批评方方日记道听途说抹黑抗疫也不成立。
最后,插几句题外话,认为方方日记会给“境外反华势力”递刀子的人,确实是多虑了。就我和各个国家的人打交道的经验,欧美国家的人基本不关心本国以外的事情,他们最关心的是本国政府的措施会不会影响自己的利益,并且随时准备游行示威。所以,我可以很有信心的说,欧美会看《方方日记》的屈指可数。
在国外这么多年,再加上时不时的旅行,我经常碰到在国外的中国人询问老外对中国的看法,而尚未碰到一次老外问我对他们国家的看法。说白了,别人根本不care。这世上,越是混得差的就越敏感,这一条,对个人、对民族都适用。
这一两百年,我们确实是挨过打、也穷过,虽然现在日子好多了,但寒门心态还是一时半会儿还是改不过来。不过改变这个现状也简单,继续发展,继续过好日子,过上个50年100年的,习惯了,也就不再敏感了。
所以,现在最重要的事情是,继续发展,别开倒车。

.png)

