




各网络公司既要确保消除非法信息,又要避免影响用户正常使用,怎样同时实现这两个目标?
许多中国互联网公司对自己的内容审核部门有着复杂的感情,因为其他业务可以赚钱,审核则和法务、合规一样会增加经营成本,但它就像安全带对司机一样必不可少。
随着互联网用户和内容的激增,审核技术也需与时俱进。今天,中国网民规模已达 7.13 亿,社交网络渗透率达 85.8%,仅用黑名单和禁词表远不能胜任日益复杂的网络环境,各大互联网公司都需要投入更多的资源,才能应对层出不穷的挑战。
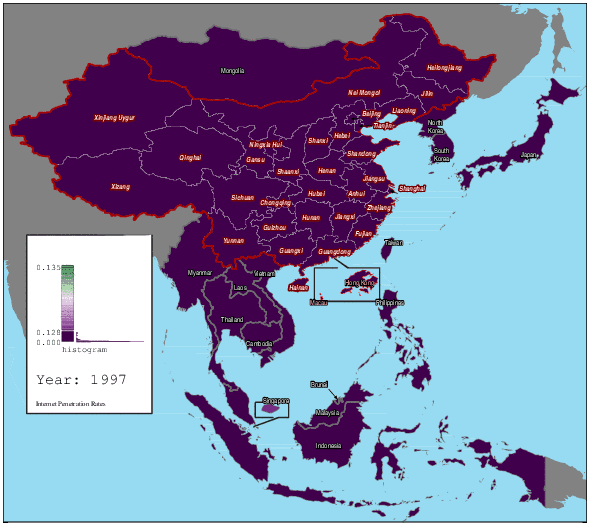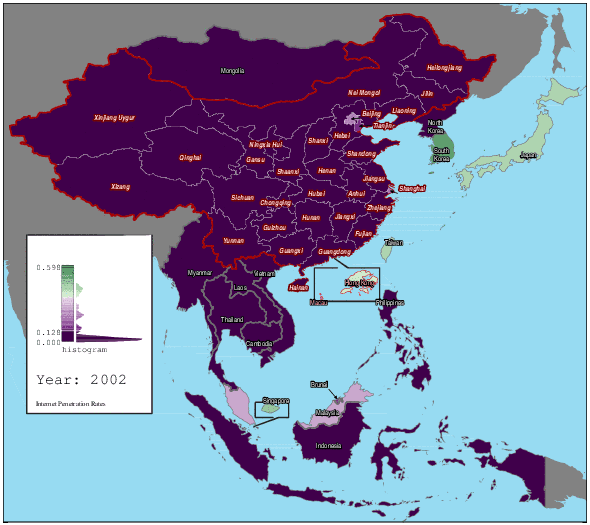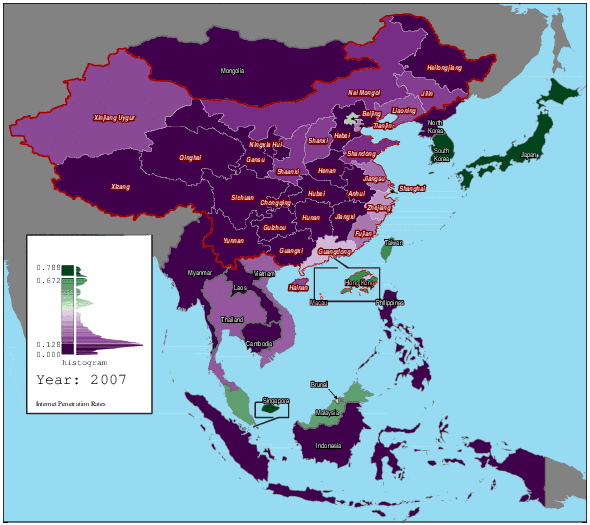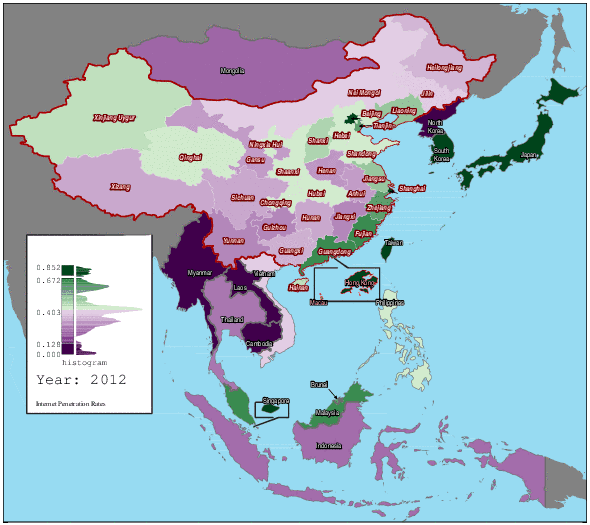
1997 年至 2012 年东亚及中国各地区的互联网渗透率变化(图片来自:hanteng,wikimedia)
消失的非正常内容
尽管 1987 年中国就已成功对外发送第一封电子邮件,但直到 1996 年 1 月,中国公用计算机互联网(CHINANET)建成,互联网才正式进入民用市场。
同年二月,国务院发布的《计算机信息网络国际联网管理暂行规定》就已有相关规定,当时的方式还比较传统,如屏蔽非法网站、人工审核门户网站新闻等。
禁词表第一次介入网民生活,是因为即时通信应用的快速发展。
1999 年,腾讯仿造美国软件 ICQ 开发并发布了 QQ 前身 OICQ,并在竞争中胜出,仅两年后就拥有了 100 万最高同时在线用户,四年后达到了 1000 万。
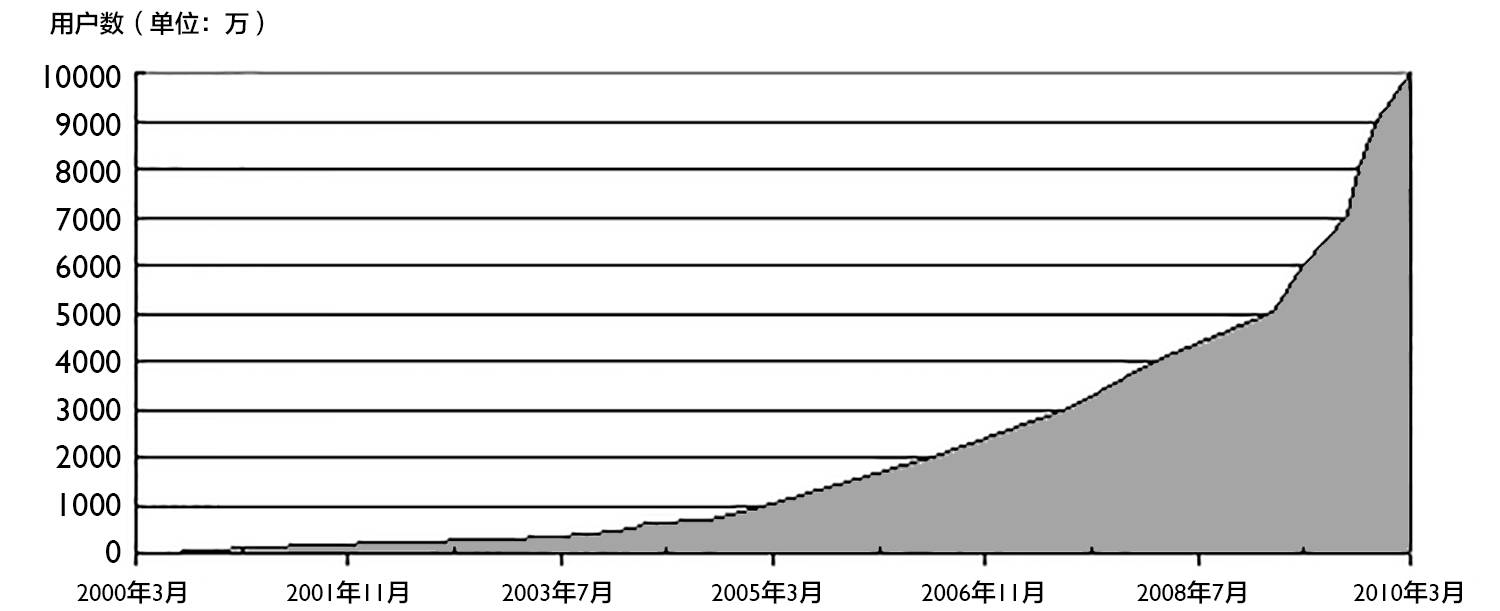
2000 年至 2010 年腾讯 QQ 最高同时在线用户数
和今天主要用于熟人通讯不同,早期互联网是陌生人社会,人们在 QQ 上通过聊天室认识新朋友。非法信息第一次拥有了大规模传播的可能性,因此禁词表应运而生。
作为最原始的非法信息拦截方法,禁词表的规则相当粗暴——只要文本内容包含禁用词,则文本无法发送,或发送后仅自己可见。由于部分医疗健康类内容很容易因为关键词被判为色情内容,它们除了站方主动发布,基本不可能个人发送张贴传播。
直到今天,微信也仍然沿用这一规则:无论是私聊、群聊还是朋友圈,只要命中该词,则该内容只有自己能看见。好在微信环境相对封闭,内容审核级别并不高,根据多伦多大学的研究者在 2016 年 11 月发布的报告,他们只发现 178 个禁词,且仅针对用中国大陆手机号码注册的微信号。
但禁词表很快就力不从心了。随着 Web 2.0 时代的到来,任何信息都有可能一夜间传遍全网。博客、论坛、社交网络开始成为互联网主流,在人人都能成为创作者和传播者的理念下,无论是用户、内容还是非法信息的传播风险,都出现了指数级增长。

在 Web 2.0 时代,分享互动行为占据了主导
这样的背景下,传统禁词方案的缺陷开始暴露出来。
首先,完善词库就很考验水平。因为官方并不提供标准的禁词表,每家公司只能独自摸索设置哪些关键词才能有效屏蔽非法信息。这就要求词库建立者必须有非常广阔的视野,密切跟踪各类非法信息传递方式的升级,随时更新词库。
另一方面,词库只能做到精准匹配,对原词的同音近型替换或词义演绎则很难处理。例如“泡面”等词就显然无法进入禁词表,否则将误伤大量正常内容。
除此之外,许多需要清除内容也并非单个词,而是事件,需要多个词同时出现,才能触发机制。
以“金正男机场遇刺”为例,则需要“机场”、“金正男”、“遇刺”其中两个词同时出现才能触发清除机制。这就给了其中单个词相当大的替换空间,例如“机场金大胖”、“胖熊机场一日游”,都可以让人联想到该事件。

同时,“2001 年金正男在日本成田机场被遣返”这样的老新闻也会被误伤
面对这些复杂情况,互联网企业不得不聘请大量专员来人工处理。他们相比机器,不仅成本高昂,且效率低下。于是,各种计算机算法被研究了出来。
进击的算法
在程序员的眼中,中文天生就比英文等表音书写语言有更高的识别难度。
除了在传统禁词规则下会出现“一台独立服务器”被识别出“台独”等低级错误外,如果要对文本进行分析,必须先对其进行分词处理。这是因为中文单字与整句含义差别极大,只有成词,才能理解和判断文本倾向,避免把正常的生理卫生知识识别为色情信息。

正确断句是小学语文老师就开始强调的内容
而英文等表音书写系统则不存在此问题,因为其文本必须通过分词确定发音的首尾,否则难以阅读,所以英文自带分词。而中文作为意音语言,每个字都独立发音,则没有在文本上分词的动力。
实现分词的基础是字符匹配,如传统的“正向最大匹配法”即是从左到右扫描文本,与机器词典进行匹配,再将匹配成功的词切分,直到无法匹配为止。
但这种方法并不可靠,如“一台独立服务器”就还是会被分为“一/台独/立/服务器”。为解决歧义问题,则需要对大量真实语料进行统计,计算每个词的出现概率,再计算不同分词方案下的总概率。
在之前的例子中,因为“立”作为词的出现概率极低,因此“一台/独立/服务器”的概率将明显高于“一/台独/立/服务器”。更进一步,还可计算两个词同时出现的概率,以得到更精确的分词结果。
今天的分词算法可以成功识别插入特殊符号的非法信息。而配合扩展词表,也可以处理以同音字或拼音替代的信息。但对于联想类词语和事件类内容,还是需要其他算法的加持。
贝叶斯方法就是其中之一。1763 年,英国学者托马斯·贝叶斯生前的一篇关于“逆概论”文章中提出了贝叶斯公式。
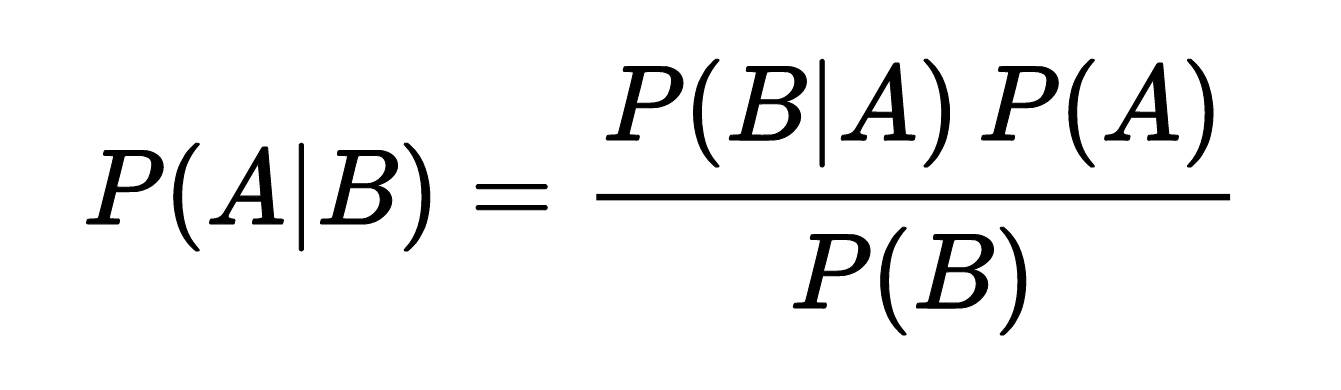
贝叶斯公式
贝叶斯方法的核心在于通过已知事件的概率(先验概率)计算未知事件的概率(后验概率)。以“金正男机场遇刺”举例,假设抽取十万条包含“机场”的文本,其中七万条为正常内容,三万条为需要清除的非正常内容。
即正常评论的概率 P(g)=70%,非正常评论的概率 P(b)=30%。
再对所有文本进行分词,计算每个词出现的概率。假设“遇刺”在七万条正常内容中,有七十条包含该词;而在三万条非正常内容中,有三百条包含该词。则“遇刺”一词出现的概率 P(W)=0.37%,在正常内容中出现的概率 P(W|g)=0.1%,在非正常内容中出现的概率 P(W|b)=1%
那么,一条提到了机场的内容里出现了“遇刺”,该内容是非正常内容的概率 P(b|W) 是多大呢?根据贝叶斯公式 P(b|W) = P(W|b)P(b) / P(W) = 81.1%。
按此方法可以计算出每个词的非正常概率,再根据下公式就可以计算出该文本为非正常内容的期望,在根据实际情况设定阈值进行处理。
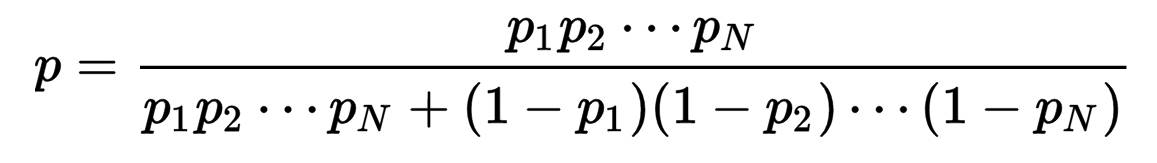
公式中 p1-pN 指的是该文本中每一个词的非正常内容概率
以“金大胖在机场遇刺”为例,假设这几个词的非正常内容概率分别为 P(b|金大胖)=0.9,P(b|机场)=0.3,P(b|遇刺)=0.8,则可算出文本是非正常内容的概率为 93.9%。
而“1963 年 11 月 22 日下午,他在机场听到了肯尼迪遇刺的消息”,则会因为“1963 年”、“肯尼迪”等词大大降低该文本的命中概率。
贝叶斯方案的缺陷是需要大量语料数据作为其先验概率的支撑,因此在许多规模较小的互联网社区并不普及。
多媒体内容的挑战
非法内容不仅仅只有文字。随着智能手机的普及和带宽速度的提升,大量的图片、音频和视频开始被制作上传,成为互联网主流内容。
对于这些新形式,应该如何处理?
最常被审核的是图片里的文字。此时,中文对英文的识别难度又一次体现了出来。识别图像中文本的算法被称为 OCR(光学字符识别技术)。这项早期用于帮助盲人阅读的的技术发展至今,对于常见的书写系统已经实现高于 99%的准确识别率。
尽管如此,仍然可以用模糊、变形、粘连、添加干扰符号等方式让 OCR 难以正确识别。因为中文字符数量远超英文字符,而每个字符都可能成为 OCR 算法的潜在错误选项。
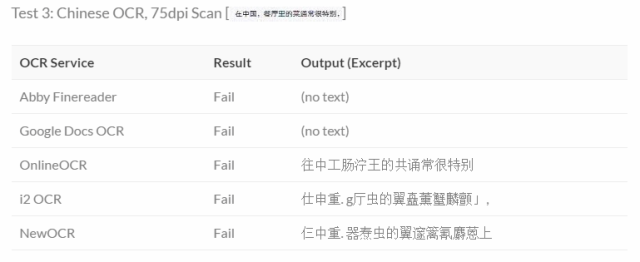
一项对 5 个中文 OCR 软件的测试结果(2015 年 6 月)
但深度学习技术的快速发展,正在改善中文 OCR 的问题。
深度学习(Deep Learning)可以追溯到 1958 年的感知机算法,但直到 2010 年后,才开始在语音和图像识别取得重大突破。通过从“边缘—部分—全体”的分层特征提取,深度学习可以做到远超传统算法的识别精度。
对于 OCR 算法最头痛的预处理阶段,通过千万量级的文本图片对模型进行训练,可以有效的实现文本的降噪和分割。对色情类图片和视频也是如此,今天的鉴黄应用准确率已经达到了 99.95%,其训练方法和 OCR 唯一的不同在于,色情内容训练库难以自动生成,需要依赖大量的人工标注。
相对比较棘手的情况是特定人物头像和人物表情包。因为许多人物并没有足够丰富的图像资料用来训练,因此目前的人脸验证算法还是相对传统:校正图片—提取初始特征——计算两张人脸的相似度。
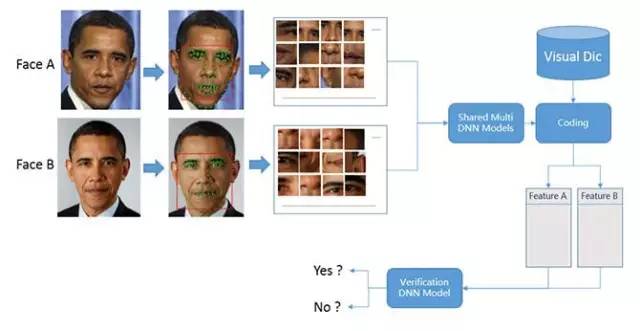
人脸相似度计算流程
非色情类视频的鉴别难度也在于此,因为不像色情内容一样能够拥有庞大数据用以训练,且惹事原因也五花八门,难以统一共性。
因此,此类视频的清理相当粗暴——直接封禁视频文件的 MD5 值。MD5 算法是一种加密散列函数,对任意字符串都能生成一段对应且唯一的 32 位十六进制数字串,即 MD5 值。因此,每个文件都有其独一无二的 MD5 值,这也意味着只要封禁一个文件的 MD5 值,则该文件的所有复制版本都无法观看。
当然,躲避 MD5 封禁也很简单,只要稍微修改文件,MD5 值即会发生改变。
除了传统社交网络的多媒体内容,语音问答和视频直播等新内容创业公司更需要保持警惕。2016 年 8 月,某风头正劲的语音问答平台突然无法访问,直至48天后才重新上线。不进增加了举报功能,其所有语言回答都需要经过审核后才能发布。
而直播平台涉黄被约谈整顿的新闻更是屡见不鲜。在竞争激烈的业态下,甚至有直播公司安插人手去敌台色情直播。好在面对强烈的业务需求,各大云服务公司都建立了完整的直播审查系统,面对色情内容可以做到秒级响应。
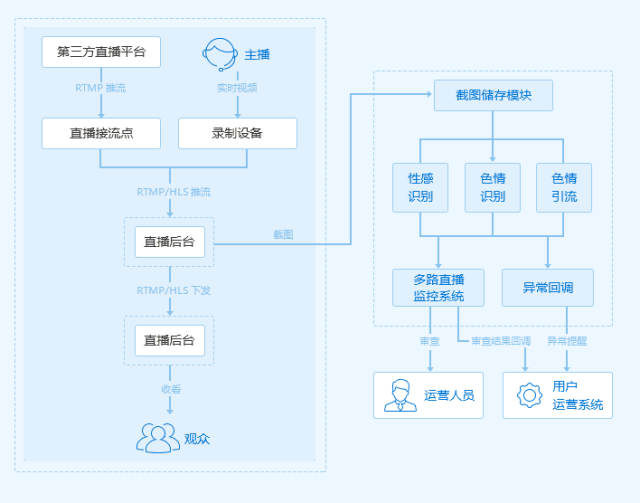
某云服务平台提供的直播审查系统
在深度学习算法逐渐成熟的今天,再也没有什么内容是无法识别的,距离完美安全的网络世界,差的只有更多非法信息的样本,只要敏感词和敏感图片源源不绝,清除网络非法信息的能力就会在它们的考验和训练下不断提高。








