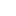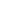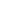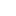探索推荐引擎内部的秘密,第 1 部分: 推荐引擎初探
图 1. 推荐引擎工作原理图 图 1 给出了推荐引擎的工作原理图,这里先将推荐引擎看作黑盒,它接受的输入是推荐的数据源,一般情况下,推荐引擎所需要的数据源包括: 要推荐物品或内容的元数据,例如关键字,基因描述等; 系统用户的基本信息,例如性别,年龄等 用户对物品或者信息的偏好,根据应用本身的不同,可能包括用户对物品的评分,用户查看物品的记录,用户的购买记录等。其实这些用户的偏好信息可以分为两类: 显式的用户反馈:这类是用户在网站上自然浏览或者使用网站以外,显式的提供反馈信息,例如用户对物品的评分,或者对物品的评论。 隐式的用户反馈:这类是用户在使用网站是产生的数据,隐式的反应了用户对物品的喜好,例如用户购买了某物品,用户查看了某物品的信息等等。 显式的用户反馈能准确的反应用户对物品的真实喜好,但需要用户付出额外的代价,而隐式的用户行为,通过一些分析和处理,也能反映用户的喜好,只是数据不是很精确,有些行为的分析存在较大的噪音。但只要选择正确的行为特征,隐式的用户反馈也能得到很好的效果,只是行为特征的选择可能在不同的应用中有很大的不同,例如在电子商务的网站上,购买行为其实就是一个能很好表现用户喜好的隐式反馈。 推荐引擎根据不同的推荐机制可能用到数据源中的一部分,然后根据这些数据,分析出一定的规则或者直接对用户对其他物品的喜好进行预测计算。这样推荐引擎可以在用户进入的时候给他推荐他可能感兴趣的物品。