




今年8月1日铁道部发布消息称,京沪高铁运营以来始终 平均上座率达到107% 。而此前有媒体报道,京沪高铁现在“每趟都有大量余票”,二等座、一等座都出现超过70%的剩票。消息一出,就立刻引来媒体和乘客大规模质疑,许多人不理解上座率为什么会超出100%,难道高铁也有站票?而乘坐过高铁的乘客也对此消息表示怀疑,不少乘客表示乘坐高铁时明明看到很多空座,为什么上座率会这么高?
铁道部的不合理算法
根据铁道部的解释,“平均上座率”是指购票上车的旅客人数与列车定员的比率。
以CRH3C型动车组为例,该车定员556人,如果开行上海至南京直达列车,在上海有480人购票上车,上座率为480/556=86%。如果不是直达列车,该车在上海有480人上车,在苏州停靠时下车400人、又上车100人并坐到终点,尽管到南京站时该车仅有180人,但是该趟车的上座率应计算为(480+100)/556=104%。
在这个例子中,上海到南京的直达车,座位占有率(556个座位被480名乘客始终占据)和上座率是相同的,都为86%,它较为客观地反映了列车的上客率和运载情况;而上海-苏州-南京的动车在后半段平均三个座位才有一个人(苏州到南京段共有乘客180人,而座位数是556),在座位占有率只有不足1/3的情况下,上座率居然高达104%。如果不仔细研究,“上座率”这个数据还真很容易给人带来能客观反映列车运载情况的错觉。
事实上,上述方法计算出的上座率与动车在起点和终点之间停靠站台数有很大关系,如果是直达车,上座率不会超过100%;如果中间停1个站,理论上最大上座率就会上升至200%(始发站满座,所有乘客在中点站下车,然后再上满旅客);如果中途停2个站,最大的上座率可以达到300%。以此类推,中间停靠的站越多,上座率的上限就越高。如此看来,一辆一路上都只有很少乘客的列车也可能会超过100%的上座率,这显然很不合理。
设计一个合理的上座率算法
既然现成的不合理,那死理性派就来设计一套合理的算法。为了更直观的反映列车的利用率,我们选择其他的计算方式。在原先的计算方法里,一个座位可能会被重复计算数次。一个简单而有效的改进办法是按里程加权平均,也就是说列车运行全程中,不管几个乘客在一个座位上乘坐过,这个座位的上座率都按照 (此座位所有乘客乘坐的里程数之和)/(全程里程数) 计算。这趟列车的平均上座率等于
(所有乘客乘坐的里程数之和)/(列车座位数乘以全程里程)
回到前面的例子中。假设南京到苏州与苏州到上海的距离比例是6:4,那么平均上座率就是
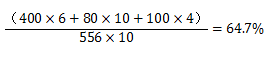
这样算,任何情况下“平均上座率”都不会超过100%。同时它也较为直接地反映乘客的座位占用率和列车使用率。
国际上的算法是怎样的
实际上,国外铁路也大多是采用类似上面的方法来计算平均上座率。在EEA(国际环境署)的 官方网站 上,与“上座率”功用相同的统计数据叫做列车的乘客占用率(occupancy rates of passenger vehicles)。它用来说明大规模旅客运输上列车的效率变化。对于单个乘客来说,EEA给出的列车占用率的定义是:乘客在车上行驶的公里数(passenger-kilometres)和列车行驶总公里数(supplied vehicle kilometres)的比值。相应的,列车完整一次运行路线的乘客占用率就是所有乘客列车占用率的平均。这个方法和前面叙述的合理算法是一致的。
在美国,专门负责管理全国火车营运的机构“全国铁路乘客公司”( Amtrak,简称“美铁”),计算列车乘坐率(percentage capacity)的 方法 则是用 乘客里程数 除以(所有座位数×列车运行总里程数) 或者计算 所有乘客占用座位数的时间 与(列车运行总时间×所有座位数)的比值,这和EEA的方法几乎相同。
而铁道部曾表示,在上座率的统计上,铁道部使用的是 国际上一贯采用的铁路统计口径 。但实际上,我们已经看到,铁道部采取的标准与国际惯例相差甚远,所给出的单一的统计数据,无法反映客观事实。
数字的欺骗性
就像铁道部计算出的高铁上座率一样,数字常常会像变魔术一样,掩盖和扭曲部分事实。
就拿最常用的平均收入来说,如果某个小镇只有20户人,平均每户的年收入是1万元,突然有一天其中的一家发了财,年收入由1万元变成21万元,全镇的平均收入就会因为这户人家的暴发立刻翻一番,变成2万元。可是这对于小镇里其余19户并没有多大影响,他们的收入还是老样子,可见只统计平均数未必靠谱。
而此时我们可以引入另一个指标——中位数来衡量。把小镇里的所有人的收入由高到低排列,最中间的那个收入(或两个的收入的平均数)就是中位数。这样一来即便出现了一个暴发户,收入的中位数也不会有太大波动,它更贴切地反映了这个小镇居民的整体的收入情况。
关于平均收入还有这样一个奇怪的结论:对于两个穷富不同的国家,只要富国的穷人移民到穷国,两个国家的人均收入就都会提高。
比如A国人均收入是20000元,B国人均收入是10000元,如果A国有一个收入15000元的人移民到了B国,他就从在A国的“无产阶级”变成了B国的“一小部分先富起来的人”,相应的,A、B两国的平均收入都会得到提高。这种有点不可思议但确有可能发生的事正说明了数字在某些时候的不靠谱与片面性。
再比如随处可见的百分比增长率,对于同样的增长率,解读方式的不同可以带来完全相反的结论,比如下面这个例子。
“去年,咖啡价格上涨了2%,今年,咖啡价格上涨了3%” A:仅仅多上涨了1%而已,这样的上涨幅还是很稳定的嘛。 B:不对,今年的上涨率是去年的1.5倍,意味着上涨率提高了50%,不是小数目。
你觉得A和B到底谁说的对呢?
由此可见,不管对于上座率、平均收入、增长率还是其它各种统计数字,在不知道它们是怎么得出的情况下只靠直观感觉理解远远不够,还要像死理性派这样仔细分析一番才可以得到符合实际情况的结论。否则这些数字难免就会成为一片让你不见泰山的障目之叶。
参考资料:
《绳长之谜——隐藏在日常生活中的数学》罗勃•伊斯特威,杰里米•温德姆
图片来源: 网易
本文由自动聚合程序取自网络,内容和观点不代表数字时代立场








