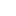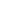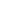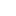方可成 | 香港“遮打革命”中的新闻实验
社会运动中,信息的收集和传播非常重要。随着技术的进步和理念的更新,收集和传播的手段也在不断更新。正在香港发生的这场“遮打革命(umbrella revolution)”中,就已经出现了不少新鲜的现象。无人机拍摄视频迄今为止,这场运动中最震撼人心的影像莫过于几段由无人机(drone)从空中拍摄的视频。载着镜头的无人机缓缓上升,从低空掠过,记录下那聚集在道路、广场、天桥上的人海,那高耸入云的摩天大楼,还有那璀璨的夜景,不仅是美学意义上的佳作,更让人从一个前所未有的视角领略到了运动的样貌。这组视频的作者是Nero Chan,他并非新闻机构的专业记者,有的报道中甚至称它为“围观者(bystander)”。但是,他发在Facebook上的这几则视频,已经传遍了世界各大媒体和社交网络。(上图来源于Nero Chan的Facebook)新闻实验室(微信公号:newslab)曾两次介绍无人机在新闻现场的应用,在账号注册后的第一次推送中即有提及。如果没有读过的话,点击这里和这里。过滤谣言,验明真相社会运动中的信息混乱,流言传播不可避免,更有人故意在人群中和社交网络上释放谣言。也因为此,人们对于真相和可信赖信源的需求愈发强烈。香港大学新闻及传媒研究中心的一些大二、大三学生自发建立了一个名为“HK Verified”的Facebook专页,进行独立的消息查证,用双语发布已经得到证实的消息。短短三四天内已经收获超过十万个赞。这个项目还采用了众包的方式,建立了一个Google文档供网友提供“可信赖和可验证”的消息。这并不是完全新鲜的尝试。此前,在西方的不少社会运动中,也有类似的独立媒体出现。不过,信息的查证不是一件简单的事情,这群新闻专业学生在获得关注后能否不负期待,做到真正独立、客观的信息查证,挑战很大。不过,做这件事情的也不只港大学生,另一群关心这场运动的人,也建立了一个“谣言追追追”的Facebook专页,专门发布已经证伪的谣言,提醒大家不要再相信。除了“HK Verified”之外,港大新闻及传媒研究中心的学生对这场运动的报道项目还有很多,可谓真正的在参与中学习,详情可点击这里。利用社交媒体的大数据做报道9月30日,《经济学人》网站的每日图表栏目用一张折线图展示了这场运动给微博带来的影响:小秘书们的工作量陡然增加。在9月28日之前的几个月,每一千条微博中大概只有4条左右会被删除,而9月28日当天,这个数字激增到了15条。这一图表的数据来源于港大新闻与传媒研究中心的Weiboscope项目。该项目自2011年1月起就开始运行,它利用新浪微博的API抓取数据,主要关注粉丝在1000以上的用户,以及经常被删帖的用户。仅2012年的一年间,该项目就收集了2.26亿条微博,其中1090万条被和谐。这些数据可以在项目网站上下载。同样,这也不是一个新的项目和新的数据库,但具体到这一运动中,却提供了一个非常有趣的观察视角。利用社交媒体的大数据做报道当然不限于关注审查。随着运动的进行,相信还会有更多作品出现。现场实时传送全世界的支持声音身处香港之外的地方,要想远程参与运动,不光可以在社交媒体上分享消息,还可以直接将自己想说的话送到运动现场——通过这个名为“并肩上Stand By You”的网站,全世界的人都可以发送信息,这些声音将被投影到运动现场的墙上和街道边的LED走马灯屏幕上。可以想象,在运动现场读到来自世界各地、用各种语言写下的鼓励话语,对于参与者来说是非常有效的支持。在街头运动中,“实体”的存在非常重要,它无法被电子化的信息所取代。这一项目很好地打通了线上的虚拟空间和线下的实体空间,制造了一种全世界关心这场运动的人跨越时空共同在场的想象。昨天,在宾大的“媒体与社会运动”课程上,我们也发送了一条信息,告诉街道上的香港人:我们整节课都在关注和讨论你们的行动。Firechat搭建新的通讯网络随着运动的开始,一款名为Firechat的APP在香港的下载量激增,冲至排行榜首位。它的特点是:不需要接入手机或WIFI网络,只要利用手机本身的蓝牙或无线功能,便能与身边的人组成一个网络,成为其中的一个节点。自然,这种网络受物理距离的限制,但也正因此非常适合在人群密集的社会运动中使用。它不仅可以不受手机网络切断的影响,是真正的去中心化网络,而且加入的节点越多越稳定。自然,这是一件技术产品,并非媒体产品。但是,这一技术提出了许多新的关于传播的问题,也为群体之间的信息传播提供了新的可能性。除了以上几例之外,部分媒体也出品了一些数据新闻作品,例如RTHK的时间表和地图、南华早报关于Twitter上香港相关话题传播速度的信息图。我本人并不在香港,以上消息也是根据各种渠道的阅读获取和总结的。如果你知道其他的新鲜实验,请告诉我一声,我会继续整理,与大家分享。◆本文首发于方可成的微信公众账号“新闻实验室 The News Lab”。欢迎关注,期待与你产生化学反应。关注方法1:打开微信,选择“扫一扫”,扫描下面的二维码关注方法2:打开微信,在添加朋友中搜索newslab