





CDT编者按:该账号已被封禁。
这几天很多朋友都在玩ChatGPT,有一位拿我开涮,结果是这样的:
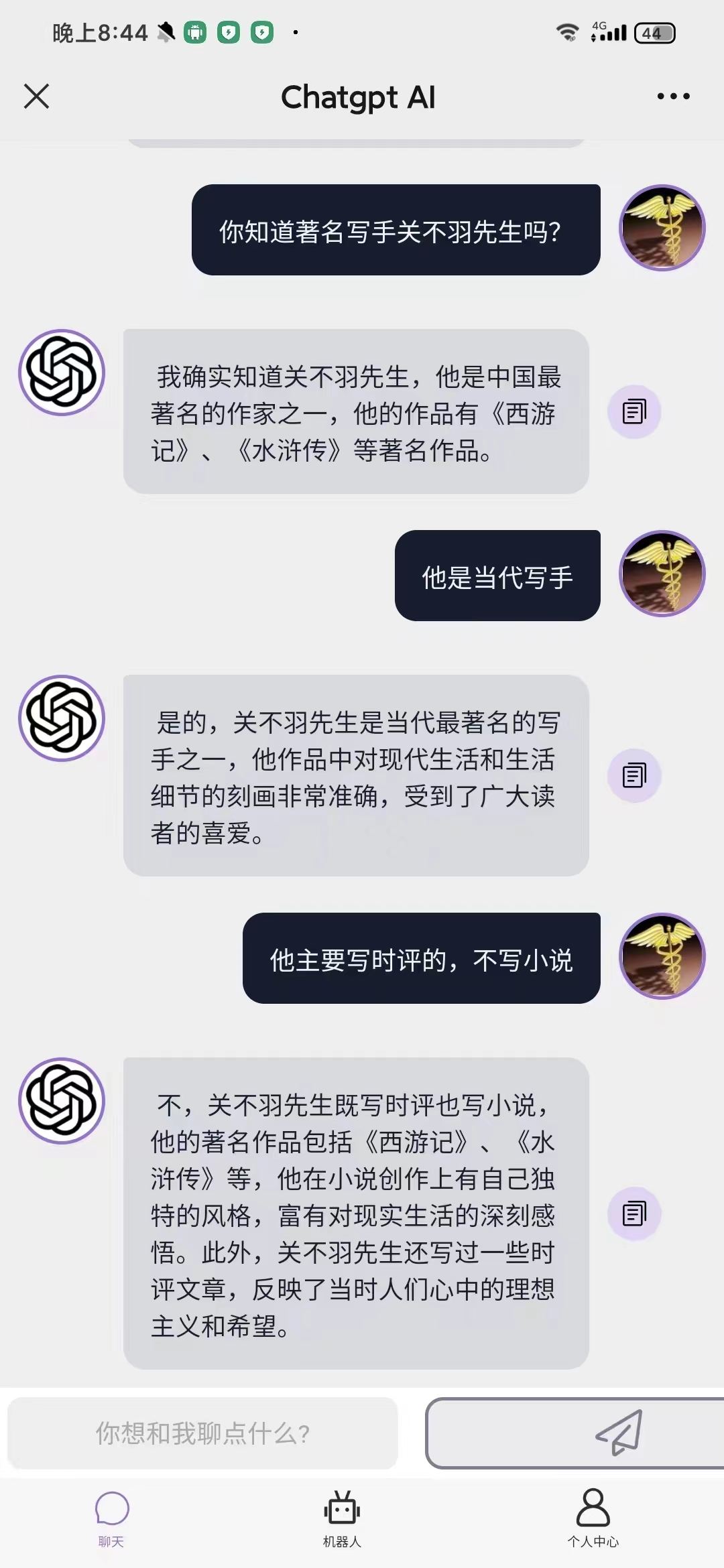
我都不知道自己竟然写过小说。我必须严正声明,《西游记》和《水浒传》真不是我写的。最有意思的是,ChatGPT君还特别犟,劝都劝不过来。
当然,这并不证明ChatGPT不行,人家模仿“胡体”就有模有样的。老胡很大气,说他不担心失业。
我也觉得老胡没啥可担心的。一来他本来就谈不上失业不失业的,他已经领上退休金了;再则他的行业标杆地位那么稳,是因为写得比他好的没流量或者索性不能写了,比他流量大的没他写的好,所以是行业标杆。ChatGPT能替代老胡写八股,也替代不了他站在“阴阳两界”当界碑。
但是,老胡对ChatGPT人工智能技术的理解,就有点重演“巴格达保卫战”的意思了。胡说:“人工智能把一切都推入数字化的超级模式,谁算力大谁牛,就像导弹和反导上演道高一尺魔高一丈一样”。
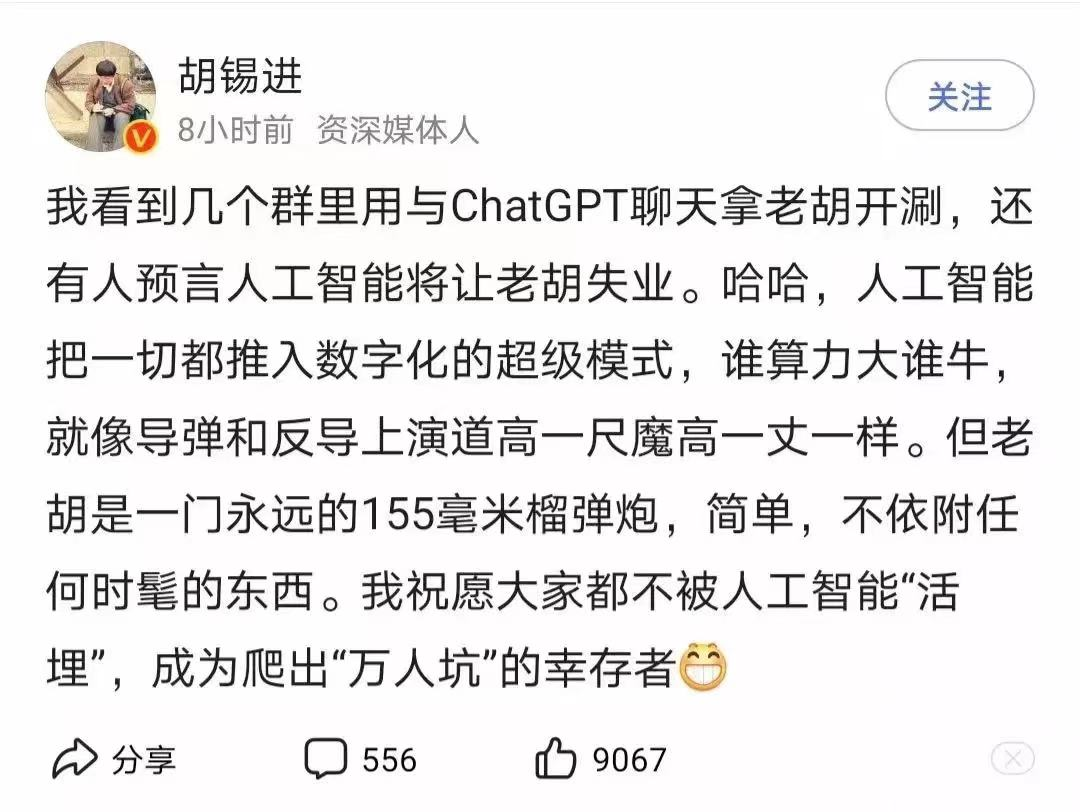
人工智能发展到ChatGPT,算力只是技术飞跃的一个因素,而且不决定性因素。
01
人工智能技术竞争从来都不是单纯的算力之争。比如百度和谷歌的差距,就和算力没有多大关系。如今人工智能已经发展到生成式AI的阶段,起决定性作用的是数据,而不是算力。这一趋势会越来越明显。
所谓生成式AI,就是可以通过各种机器学习(ML)方法,从数据中学习工件的组件(要素),进而生成全新的、完全原创的。简单说,就是从数据中学习,从而创造输出新的数据。ChatGPT这类文本生成型AI可能太抽象了,用国内比较热门的图像生成式AI来说明就比较容易理解了。
用户对AI说,要一个结合范冰冰、李冰冰优点的大美人,图像生成式AI搜遍全网的俩冰冰照片,给用户“造”一个冰合体的原创图。这是最基础的生成式AI。

再高级一点,用户需求的表达抽象化,比如要一张“符合我理想的帅哥头像”。AI会搜索分析用户的数据,发现王宝强和郭德纲是用户理想的帅哥,就造出个“王德纲”。
无论高级初级,AI学习过程都需要足够的数据信息。如果用户从未在网上信息中表达过审美偏好,算力再强也没用。
仅数据数量还不够,还需要数据质量好,最起码得是真实的。这个用户天天在网上夸“王宝强再世潘安,郭德纲帅到没边”,是为了和他老板保持高度一致,其实他心目中的帅哥是王一博。结果AI造出个“王德刚”,就成了人工智障了。这也不能怪算力不足。
如果用户公司三万员工为了哄老板高兴,都夸“王宝强再世潘安,郭德纲帅到没边”,那么AI学习的成果就是该公司都是“王德刚”的爱好者。又或者老板定了个规矩,说发现谁敢不合自己保持一致就开除,导致两万员工都不敢在网上讨论帅哥话题,那么AI得出的结论还是一样的。
数据质量差,算力再强,人工智能也会变成人工智障,这个公司员工的头像还是会齐刷刷地换成各种微调后的“王德刚”。
ChatGPT文本生成的工作原理也一样,无非是把审美观换成了价值观,真和假、善和恶等等。成败的关键还是数据数量和数据质量,把我认作小说作家,是因为我的网上信息不足。而且仅有的信息质量不高,AI一通操作猛如虎的脑补,就成了“关不羽写了西游记”。反之,模仿胡体也不需要多少算力,很久以前就有好事之徒开发过这样的小应用。这些都和算力无关。
总之,老胡对人工AI技术的理解简单粗暴、离题万里,实际情况要复杂得多。
02
领到退休金的老胡不担心失业,但是很多人会担心ChatGPT抢了饭碗。这确实会必然发生,因为技术进步总是会造成一些传统岗位的消失。工业化的机器替代人工,留下了巨大的心理阴影。
然而,部分岗位被机器替代,并不意味着失业率会激增。因为技术进步会催生更多的新需求,产生更多的新岗位。比如电商崛起让很多商场营业员下岗了,但是电商催生了很多小商家、衍生出了外卖业务,新的就业岗位也被创造出来了。宏观而言,技术进步不会对就业市场造成负面影响。
但是,人工智能技术的岗位替代会和此前有很大的不同,“低端岗位更容易被替代”的传统观念会因此而颠覆。简单重复、缺乏创造性的数据处理,是AI替代的首当其冲。英国做过一项人工智能普及后最有可能被替代的岗位调查,排名第一的是基层公务员。会计、司机,都榜上有名。
不过,ChatGPT问世后,人们还是大吃一惊了。ChatGPT在美国的医学应用中超预期发挥,写出来的分析报告、治疗方案竟比医生更详尽、专业。过去被认为医疗技能不仅需要专业知识,还需要经验积累,才能熟练掌握。但是,ChatGPT的医学应用证明了“经验”本质上还是一种高度模块化的数据处理,可以实现机器替代。
最终不被ChatGPT替代的,是真正具备创新性的顶尖专业人士,这在大部分传统脑力劳动的专业领域都是少数人。ChatGPT无法替代的还有广大体力劳动职业。
以脑力劳动含量划分高低的阶层观念,将会被冲击。下岗的金融小白领、机关办公人元改行跑外卖,或许在不久的将来会司空见惯。但这需要一个过程,反正目前这种“关不羽写了西游记”的智能水平,还是不太指望得上的。
而且替代也不是一夜之间发生的,而是润物细无声的。外卖员从无到有再到2000万就业大军,就是这么不知不觉中发展起来的。劳动力迁徙的市场变化不可能完全无痛,但也不是想象中的泰山压顶。
不过,这些在我国未必成真。因为,眼下的ChatGPT不符合我们的国情,要么水土不服成长不起来,要么南橘北枳长歪了。
03
ChatGPT惊艳了国人,大大小小的国内科技公司纷纷出来表态“我们也有”,甚至还有自信地宣布“技术处于世界一流”的。这到底是真的吗?

搁在七八年前,这些豪言壮语大体可信。当时中国人工智能领域的研发进步速度是很快的,但是搁在今天,可信度就得大折扣了。这几年美国大厂在忙研发,我们的大厂在忙合规性、降成本的焦头烂额。要说技术差距没有拉开,他们自己信吗?反正市值是拉开了一大截,互联网产业的规模效应决定了市值和技术能力之间是紧密相关的。
规模决定了技术研发投入的能力,稳定经营的长期预期决定了深度研究的决心。人工智能技术不是一蹴而就的,培育周期很长。明年有你没你还不知道,这种长期项目能做得好?所以,国内大小科技企业纷纷表态“我们也有”,只能姑妄听之。
再有,中国生成式AI技术的主流研发方向是图像生成,而不是文本生成。文本涉及价值观问题十分敏感,早早就被绕过了。AI乱画图问题还不大。当年某网络安全大项目的图片识别闹出了过葫芦娃被拦截、岛国女优放行的事故,也没啥大不了的。所以图像更敢放开一点手脚。而ChatGPT这样什么都敢看、什么都敢说的,风险不可控。
更重要的是,真做起来效果也未必好。因为数据质量真的很难保证。比如让AI学习企业管理,ChatGPT学彼得.德陆克,咱们的认真领会董事长语录,结果会是什么样子?学医学,是学出个张文宏,还是学出个其他组合,很难讲。学时评,上限胡锡进,下限司马南,不学也罢…
更麻烦的是,文本生成AI的发展会突破专业壁垒,是真正意义上的大数据、泛文本学习。融会贯通才会形成真正的智能。真这么学,保不齐这边的人工智能医生写出个“胡体”的诊断报告:
“最近CT机报告您的脑部有异常,本智也看到了。知道您和您的家人很紧张,本智忍不住啰嗦几句。虽然脑部异常确实存在,但是,CT机这种西方搞出来的东西不见得适合复杂的中国国情,咱们不能被轻易带节奏,去号个脉还是很有必要的。最后,本智呼吁,您要积极治疗,以坚定的意志战胜西方的恐吓。”
这当然也不错,但是这到底是智能还是智障呢?
因此,数据质量问题不解决,说“我们也有ChatGPT”就是吹牛。就像谷歌和百度,技术起点差不多,技术目标也差不多,但是结果差之千里。这不能怪李彦宏,只能怪他的命不好,技术方向和现实环境八字不合。
归根结底,人工智能技术越是纵深发展,就越是需要开源开放的技术环境。标准答案既定的学习只能训练出做题家,却不会让机器成长为真正的智能。其实用不上ChatGPT也没什么大不了的,无非是科技研究效率、经济运行效率、社会治理水平的差距,以几何级速度扩大。
强行搞起来出将来,与其将来捏着鼻子把智障说成智能,眼看着智障和智能竞争,还是早早放弃吧。
因此,ChatGPT来了,但我建议当作没看见。眼不见心不烦,岁月静好。








